How This Started
One of the hardest parts of a hackathon isn’t building — it’s figuring out whether your idea is actually original before you sink hours into it. We wanted a fast “sanity check” that could (1) show similar prior projects and (2) give concrete ways to differentiate.
Projects compared
~65,900
Core method
Embeddings + FAISS
Output
Score + matches + suggestions
What it does
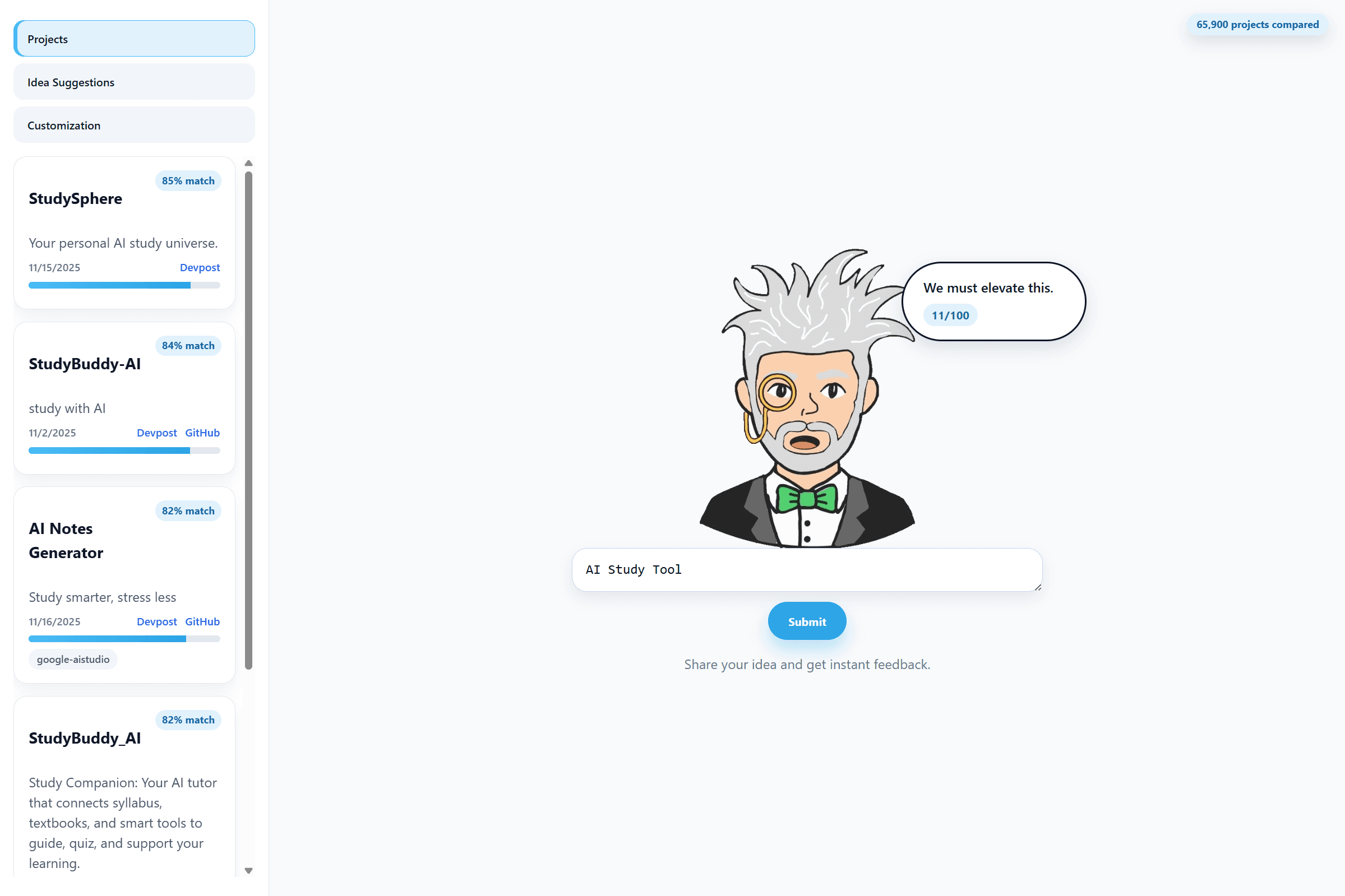
Rate a Hack takes a team’s hackathon idea and compares it against a database of past hackathon projects collected from Devpost and GitHub. It returns:
- an originality / similarity score
- a list of closest-matching projects (so you can see what already exists)
- a set of idea suggestions to help narrow scope and differentiate the concept
How it works
Data pipeline
- Harvest project data and normalize it into a JSONL corpus.
- Convert each project into a vector representation using SentenceTransformers embeddings.
- Index the vectors with FAISS for fast nearest-neighbor retrieval.
Scoring + feedback loop
When a user submits an idea:
- the backend embeds the idea text
- FAISS retrieves the nearest matches
- cosine similarity is computed against those neighbors
- an originality score is produced (calibrated to emphasize distinguishing concepts vs. superficial wording)
- the system returns:
- the score
- closest matches
- suggestion prompts to make the idea more specific / defensible
Team
Built with:
- jacobwoodworth Woodworth
- Sypitkowski Sypitkowski
- Christopher Kopiwoda (me)
My main contribution
I worked across the data pipeline and product layer of the project:
- Built the project database pipeline, including the web scraping and data structuring that generated the JSONL corpus of past hackathon projects from DevPost.
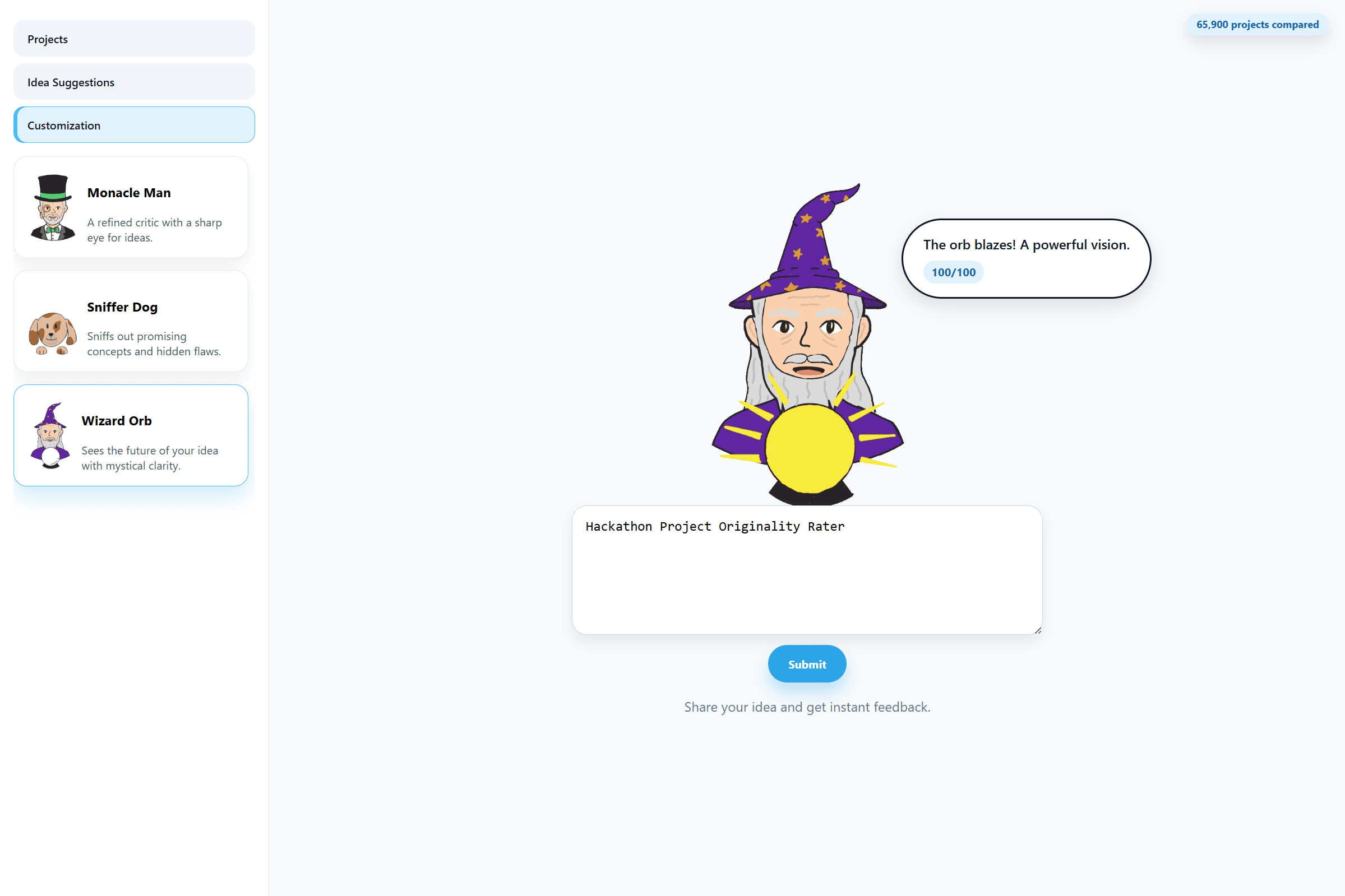
- Designed and implemented the frontend (React + TypeScript), including the character-based feedback UI, scoring display, tab system (Projects / Idea Suggestions / Customization), and overall user interaction flow.
- Helped connect the backend and frontend, wiring API endpoints to the UI, handling request/response formatting, and ensuring idea submissions flowed cleanly from the interface to the retrieval engine and back.
My focus was on making the system usable end-to-end: reliable data ingestion, a clean interface, and seamless communication between the model and the user experience.
Challenges
- Calibration: Getting a score distribution that isn’t “everything is 80% similar” required tuning weights and focusing on concept-level uniqueness.
- Data collection: Rate limits and staying within platform terms made ingestion slower and more careful than expected.
- User clarity: A single number isn’t enough — it needs examples (nearest matches) and actionable suggestions to be useful.
What we’re proud of
- A complete end-to-end workflow: idea → retrieval → score → UI.
- A reusable JSONL dataset of prior hackathon projects.
- A clean UI with hand-drawn character feedback and multiple modes (projects / suggestions / customization).
What’s next
- Deploy on a dedicated server (not local-only).
- Expand the dataset toward hundreds of thousands of projects (ideally all of Devpost).
- Make the score more explainable (e.g., highlight which concepts/features contributed most to similarity).
Media & Documentation
UI Screenshots
1 / 4